Bayesian Model Selection - Nested Sampling#
Nested sampling is a Bayesian model selection algorithm first developed by John Skilling in 2004. [1] It calculates an estimate for the Bayesian ‘evidence’ for a model, from which one can obtain other useful information such as the best fit values for a set of parameters.
It works by sampling points in the parameter space and calculating how well the parameter values at each point fit the experimental data given. This fit is proportional to the “likelihood” that these are the correct values. It then takes the worst fit point and sets that as the “least likelihood”, and replaces that point with one with a better fit. The process is then repeated. In practice, this means that the space where we take our samples from becomes a smaller space containing better and better fitting points, until either a certain number of iterations have been performed or until a tolerance threshold has been passed.
In the literature, the points which are kept after each iteration are known as ‘live points’.
For more background on nested sampling, please see the page for nested sampling algorithms on Wikipedia, or books such as Sivia & Skilling (2006). [2]
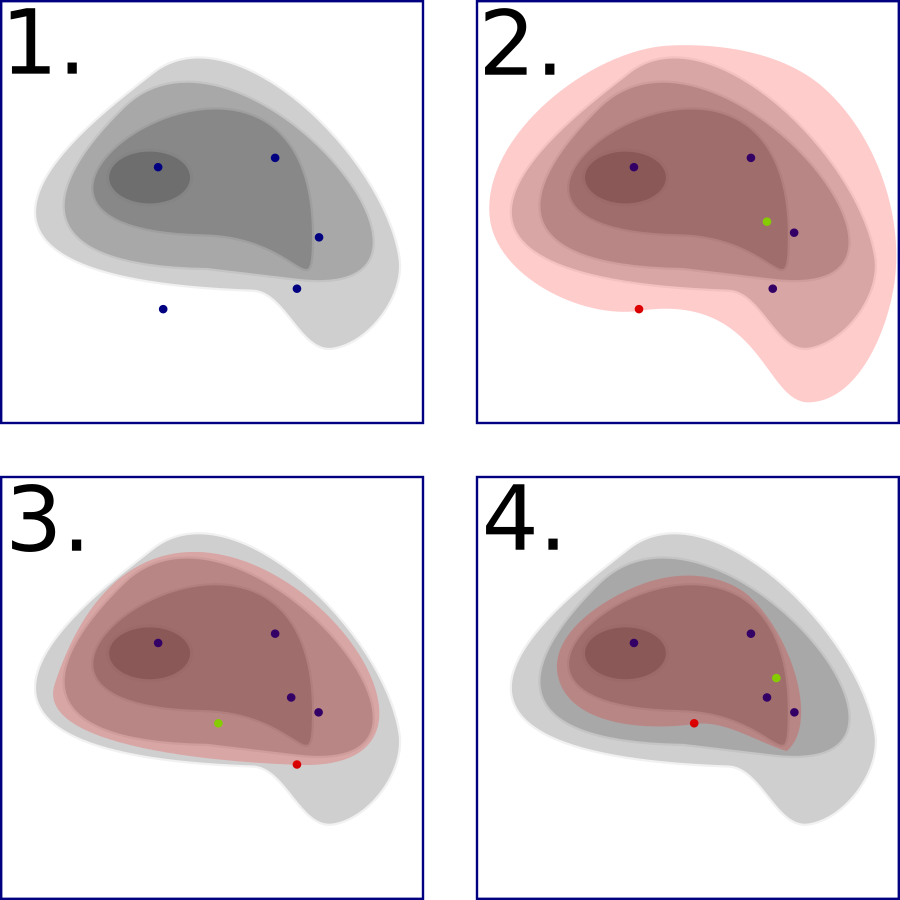
Fig. 1 Four iterations of a nested sampling algorithm on a likelihood function given by the contour. The red point indicates the least likelihood point chosen in each iteration, the green point the new point sampled, and the red shaded area is the area from which the green point could be sampled.#
Of course, unlike the diagram, we do not know our entire likelihood function in advance (else we wouldn’t need this algorithm!). The difficult part of nested sampling is figuring out how to choose our new points such that they are within the red shaded area. The method of doing this is the main difference between any two implementations of the nested sampling algorithm. Skilling’s original implementation (found in [2] or online here) did this by choosing a point at a fixed distance and random angle to one of the live points, calculating its likelihood, and accepting it as the new point if the likelihood is better than the least likelihood; otherwise, the point is rejected and the process is repeated.
The particular implementation of nested sampling used by RAT is a version of MatlabMultinest, modified to be compilable to C++ with MATLAB Coder. MatlabMultinest is a MATLAB implementation of the MultiNest algorithm [3], which efficiently selects new points by grouping the live points into ‘contours’, drawing an ellipsoid around each contour using its covariance matrix, and selecting a new point randomly from inside one of the ellipsoids.
Algorithm control parameters#
The following parameters in the Controls object are specific to nested sampling:
nLive: the number of points to sample. Must be an integer greater than zero.nMCMC: if non-zero, MultiNest will not be used, and instead new points will be chosen using an MCMC chain with this many iterations. Must be an integer greater than or equal to zero.propScale: A scaling factor for the ellipsoid. If this is larger, the algorithm is more likely to choose points near the edges of the ellipsoid rather than focusing on the centre. In some cases this may lead to better exploration of the parameter space.nsTolerance: The tolerance threshold for when the nested sampler should finish. A smaller value indicates a stricter tolerance.The convergence statistic for each iteration is
\[\log(Z + L_{max}*exp(-j/N_{live})) - \log(Z)\]where \(Z\) is the evidence, \(L_{max}\) is the maximum likelihood out of all live points, \(j\) is the number of iterations, and \(N_{live}\) is the number of live points (
nLive). This is an estimate of the most that the log-evidence can change on iteration \(j\). [4] The algorithm is considered to have converged when this value is less thannsTolerance.